Exploration des données des taxis New Yorkais avec Opendatasoft
Lisez cet article et naviguez à travers les données sur les trajets des taxis jaunes qui parcourent la ville de New York.

La semaine dernière, la ville de New York a ouvert les données des taxis New Yorkais. Les données portent sur des millions de courses de taxis. 165 114 361 courses pour être plus précis. Au moment où la guerre fait rage entre les taxis et Uber, seulement quelques jours après le clash entre le maire de la ville Bill de Blasio et Uber, cela semblait une bonne idée de jouer un peu avec ces données en les indexant dans la plateforme Opendatasoft et en les visualisant sur une carte et dans les outils d’analyse!

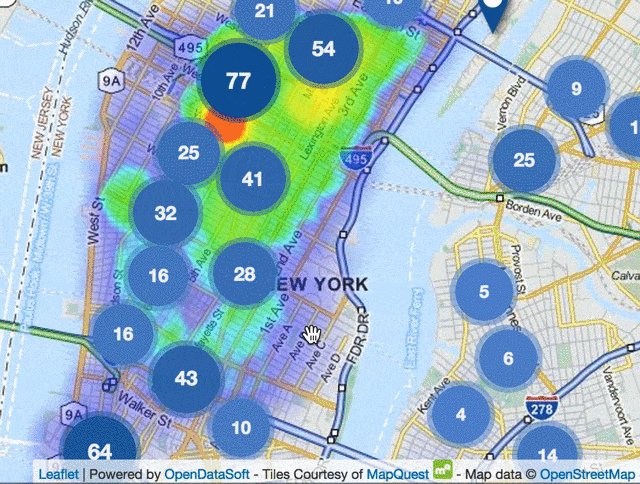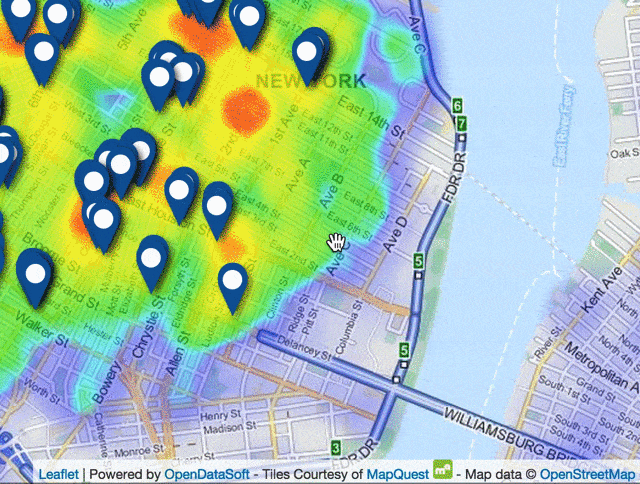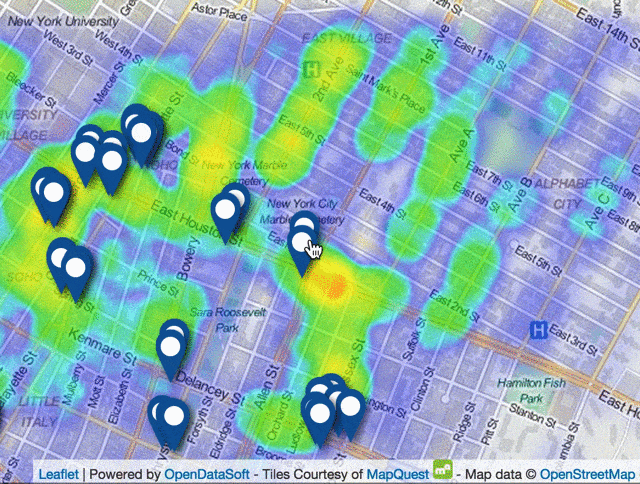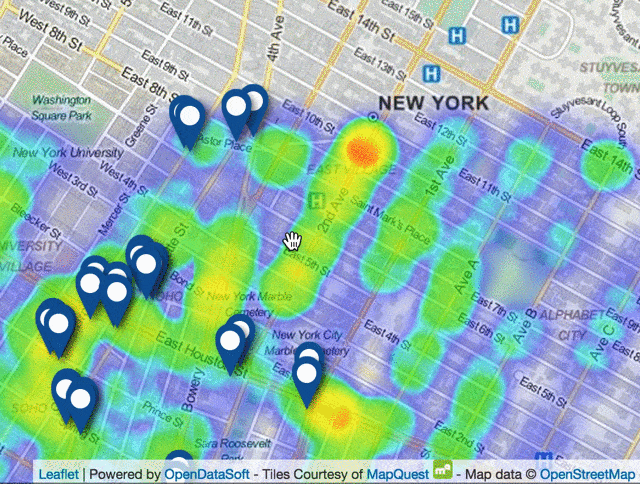
Sud de Manhattan, NYC, carte de chaleur des endroits où les usagers montent dans un taxi et points de repères des bouches de métro
Quelques faits attendus sur les données des taxis New Yorkais
Comme on pouvait s’y attendre, le nombre de courses augmente progressivement au cours de la semaine, avec un pic le samedi.

L’évolution mensuelle semble montrer un plus grand nombre de courses au printemps et à l’automne:
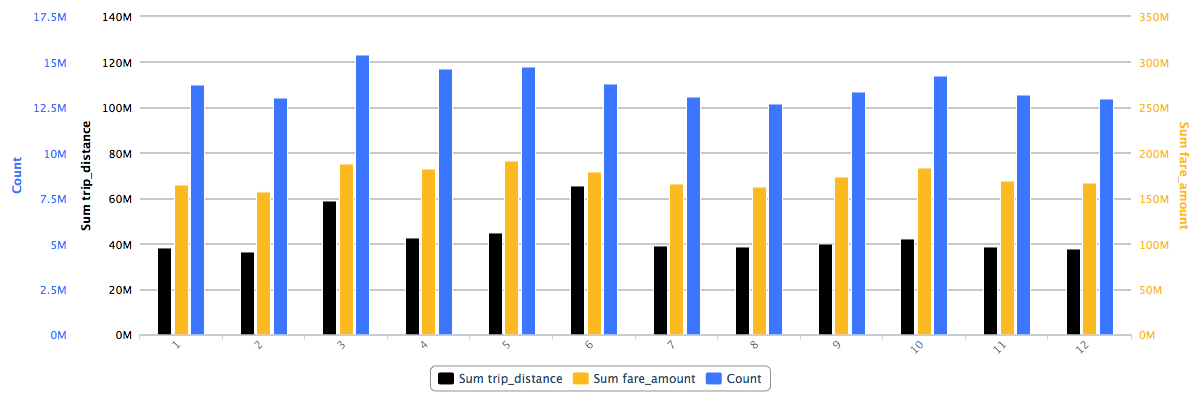
Cela sera néanmoins intéressant d’attendre les données de 2015 pour voir si on est face à une réelle tendance.
Reverse Engineering des prix des Taxis
Ci-dessous sont représentés, étant donné un prix de course (hors pourboires et péages), la distance moyenne parcourue et la durée moyenne de la course:

Il pourrait être intéressant de recréer un modèle de pricing à partir de ces données, et développer une application nous prévenant lorsque l’on s’éloigne de la norme. Ou, en filtrant par la position de prise en charge, vérifier si une partie de la population new-yorkaise est désavantagée comme certains le prétendent (en).
A propos de la qualité des données
Etant donnée la taille du jeu de données, on ne peut pas dire qu’il y ait beaucoup d’erreurs ou de données fausses. Mais les jeux de données parfaitement propres sont très rares. La visualisation ou la cartographie des données sont alors de bons moyens de trouver les données incorrectes, surtout quand on est en présence de 160 millions de lignes!
Le premier, et le plus basique, des exemples est celui des mauvaises coordonnées:

Certes Uber a lancé Uber Boat à Istanboul (en) mais la plupart des points éloignés de New York ne sont probablement pas correctement localisés.
Dans la même veine, on constate qu’il y a des courses très longues – 13 jours – qui mériteraient une petite enquête ; et des courses de durée négative qui pour le coup n’en ont pas besoin :

Nombre de courses en fonction de leur durée
Smart Cities 101
La partie la plus amusante : nous avons créé la carte de chaleur de l’ensemble des prises en charge en 2014 (souvenez-vous, ~160 millions) et ajouté un calque avec les entrées du métro. C’est assez incroyable de naviguer si facilement dans autant de données!
En intégrant un calcul d’itinéraire entre les stations de métro, on pourrait comparer chaque course de taxi avec son équivalent en transport en commun. Cela permettrait de mieux comprendre de quelle manière les usagers se comportent, pourquoi et surtout ce que la ville peut faire pour améliorer leur vie quotidienne. Cela constituerait un premier pas intelligent dans le développement d’une Smart City.