












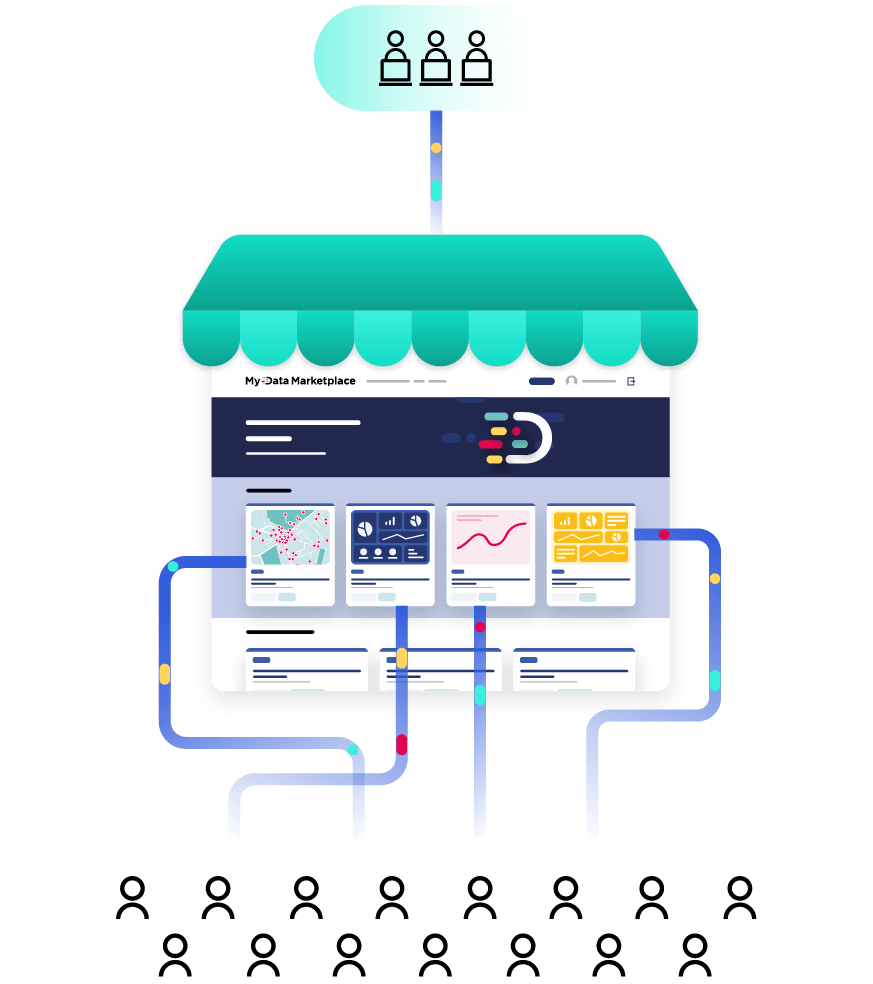















Seamless integration with your technology stack
We collaborate with technical experts to advance your data marketplace projects. Our partners bring specialized expertise in data integration, metadata management, and compliance, ensuring robust and scalable solutions. Explore the technical depth of our collaborations on our partner page.


